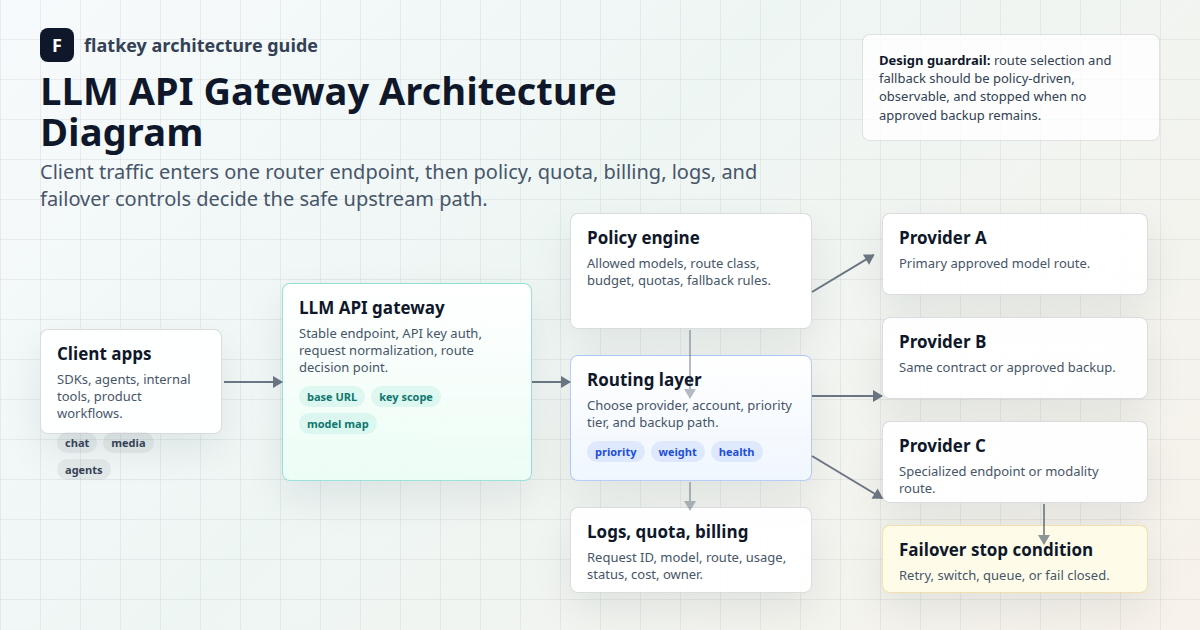
Длинные промпты — это не всегда проблема длинного контекста. Некоторые промпты следует урезать, для некоторых использовать извлечение данных (retrieval), для других — резервировать больше места для вывода, а некоторым действительно нужно большее контекстное окно. Маршрутизация по контекстному окну — это политика, которая определяет, по какому пути должен пойти запрос, прежде чем он сожжет бюджет на неправильной модели.
Цель проста: маршрутизировать по фактическому размеру промпта, требуемой форме ответа и данным, необходимым для контроля затрат. Разговор со службой поддержки на 6000 токенов, анализ контракта на 70 000 токенов и сканирование кодовой базы на 900 000 токенов не должны использовать один и тот же маршрут по умолчанию только потому, что все они доступны по одному API-ключу.
Flatkey полезен в этой схеме, потому что доступ к моделям, маршрутизацию, анализ использования, биллинг и операционный контроль проще осуществлять через единый шлюз, чем через разрозненные аккаунты провайдеров. Используйте приведенную ниже структуру для разработки правил маршрутизации по контекстному окну, а затем проверьте текущую модель, семейство эндпоинтов и единицу использования на странице цен Flatkey перед развертыванием в продакшн.
Маршрутизация по контекстному окну начинается с бюджета токенов
Начинайте каждое решение о маршрутизации с бюджета, а не с названия модели.
требуемый_контекст =
токены_системы_и_политики
+ токены_ввода_пользователя
+ токены_извлеченного_или_прикрепленного_контекста
+ токены_схемы_и_результата_инструмента
+ токены_истории_разговора
+ зарезервированные_токены_вывода
+ зарезервированные_токены_для_рассуждений
+ токены_запаса_прочностиМаршрут доступен, только если требуемый контекст помещается в используемое контекстное окно модели после того, как вы зарезервировали место для вывода и рассуждений. Руководство OpenAI по моделям для рассуждений служит здесь хорошим напоминанием: когда сгенерированные токены достигают предела контекстного окна или max_output_tokens, ответ может стать неполным, и командам следует оставлять место для рассуждений и вывода во время калибровки рабочей нагрузки.
Этот резерв важен для контроля затрат. Если запрос едва помещается в контекстное окно, модель все равно может дать сбой, обрезать ответ или потратить много средств на входные токены, прежде чем вернуть бесполезный результат. Хорошая маршрутизация по контекстному окну защищает от этого, направляя слишком большие запросы по правильному пути до того, как будет сделан вызов.
Практическая матрица маршрутизации
Используйте эту матрицу в качестве первого шага для маршрутизации по контекстному окну. Настройте пороговые значения в соответствии с вашими реальными подсчетами токенов, каталогом моделей, SLO по задержке и оценками качества.
| Класс промпта | Типичный сигнал | Рекомендуемый маршрут | Правило контроля затрат | Требуемые данные |
|---|---|---|---|---|
| Короткая задача | Маленький промпт, короткий ответ, нет длинной истории | Быстрый и недорогой маршрут | Избегайте моделей с длинным контекстом, если это не требуется по результатам оценок | Токены промпта, токены вывода, процент успешных выполнений |
| Обычный чат | Умеренная история, инструменты или структурированный ответ | Сбалансированный маршрут с поддержкой инструментов и схем | Ограничение по разговору или владельцу | Использованная модель, размер результата инструмента, процент валидных схем |
| Длинный документ | Большой файл, транскрипция, политика или контракт | Маршрут с длинным контекстом или маршрут с извлечением | Сравните стоимость полного контекста со стоимостью извлечения | Входные токены, цитируемые фрагменты, качество ответа |
| Огромный корпус данных | Множество файлов, кодовая база, логи или архив | Извлечение, разбиение на части, уплотнение, затем выборочный маршрут с длинным контекстом | Не загружайте весь корпус данных по умолчанию | Извлеченные части, отброшенный контекст, процент попаданий в кэш |
| Промпт, требующий много рассуждений | Длинная задача плюс планирование, инструменты или рассуждения о коде | Маршрут с явным резервированием для вывода и рассуждений | Резервируйте место для вывода перед отправкой промпта | Процент неполных ответов, токены для рассуждений/вывода, задержка p95 |
| Проверка на соответствие требованиям или финансовый аудит | Конфиденциальный контент и требования к аудиту | Закрепленный проверенный маршрут | Блокируйте автоматический переход на запасной вариант без одобрения | Запрошенная модель, использованная модель, владелец, трассировка затрат |
Это и есть маршрутизация по контекстному окну в действии: у каждого класса есть маршрут, правило затрат и подтверждение того, что маршрут сработал.
Не используйте самое большое контекстное окно по умолчанию
Большие контекстные окна полезны. Но они не являются бесплатной заменой маршрутизации.
Документация Google по длинному контексту Gemini описывает контекстные окна в 1 млн токенов и объясняет, как длинный контекст может открыть рабочие процессы, которые ранее требовали суммирования, извлечения или фильтрации. Документация Anthropic по контекстным окнам описывает контекст как рабочую память, которая включает в себя содержимое запроса, результаты инструментов, документы, определения инструментов и вывод. Оба момента важны: большие окна расширяют возможности, но за все, что вы помещаете в окно, все равно нужно платить, проверять и логировать.
Самый безопасный вариант по умолчанию — это не «отправлять все». Более безопасный вариант:
- Направляйте короткие промпты по эффективным маршрутам.
- Используйте извлечение, когда ответ зависит от небольшой части большого корпуса данных.
- Используйте длинный контекст, когда модели необходимо одновременно сравнивать множество частей источника.
- Резервируйте бюджет для вывода и рассуждений перед вызовом модели для рассуждений.
- Логируйте достаточно деталей использования, чтобы сравнивать стоимость за каждый приемлемый результат.
В этом и заключается суть контроля затрат при маршрутизации по контекстному окну.
Когда извлечение лучше длинного контекста
Извлечение (Retrieval) обычно лучше, когда задача требует узкого набора доказательств. Примеры включают «найти пункт о продлении», «кратко изложить этот инцидент на основе трех релевантных строк лога» или «ответить на основе текущей документации API». В таких случаях отправка всего контракта, архива логов или сайта с документацией может увеличить стоимость без повышения точности.
Используйте извлечение, когда:
- Ответ должен цитировать небольшое количество фрагментов.
- Большая часть корпуса нерелевантна вопросу пользователя.
- Один и тот же корпус многократно запрашивается многими пользователями.
- Вам необходимо ограничить доступ к данным по арендатору, проекту, команде или разрешению.
- Стоимость ввода полного контекста будет превышать ценность ответа.
Маршрутизация по контекстному окну должна сначала отправлять запрос на извлечение, а затем передавать модели только выбранные фрагменты, метаданные и инструкции. Записывайте идентификаторы извлеченных источников, количество токенов и результат принятия ответа. Если ответ не удался из-за нехватки контекста, переведите этот рабочий процесс на маршрут с большим контекстом и зафиксируйте причину.
Когда длинный контекст превосходит извлечение
Длинный контекст эффективнее, когда задача требует широкого сравнения. Примеры включают проверку полного набора политик на наличие противоречий, анализ полной стенограммы, сравнение разделов в большом контракте или использование всего репозитория в качестве справочного набора для задачи планирования.
Используйте маршрут с длинным контекстом, когда:
- Задача зависит от связей между множеством удаленных разделов.
- Модели нужна вся структура документа, а не только отдельные фрагменты.
- Качество извлечения трудно проверить до генерации.
- Источник представляет собой единый ограниченный артефакт, например, один PDF-файл, одну стенограмму или один пакет кода.
- Ожидаемая ценность ответа оправдывает более высокие затраты на ввод.
Даже в этом случае маршрутизация по контекстному окну не должна пропускать проверку затрат. Измеряйте общее количество входных токенов, количество кэшированных токенов (если доступно), количество выходных токенов, задержку, частоту повторных попыток и долю принятых ответов. Политика маршрутизации должна доказывать, что маршрут с длинным контекстом был лучше, чем извлечение, а не просто проще в реализации.
Кэширование промптов должно учитываться при принятии решения о маршруте
Кэширование промптов может изменить экономику повторяющихся длинных промптов. Документация OpenAI по кэшированию промптов объясняет, что подходящие длинные промпты могут выиграть, если статический контент идет первым, а переменный — позже; они также предоставляют cached_tokens в деталях использования, чтобы команды могли отслеживать поведение кэша.
Маршрутизация по контекстному окну должна рассматривать возможность кэширования как первостепенный сигнал:
| Шаблон промпта | Последствия для маршрутизации |
|---|---|
| Стабильная системная политика плюс множество вопросов пользователей | Размещайте стабильный контент в начале и измеряйте долю кэшированных токенов |
| Повторяющийся большой пакет документации | Рассмотрите маршрут с длинным контекстом, учитывающий кэш |
| Высокодинамичные данные, специфичные для пользователя | Не рассчитывайте на экономию за счет кэша |
| Общие определения инструментов для множества вызовов | По возможности сохраняйте схемы инструментов стабильными |
| Короткий промпт ниже порога кэширования | Сначала оптимизируйте маршрут/модель; кэширование может не помочь |
Кэшированные токены могут снизить стоимость или задержку в зависимости от поведения провайдера, но они не делают контекстное окно бесконечным. В документации Anthropic прямо делается важное различие: кэшированные префиксы промптов все равно могут занимать место в контекстном окне. Политика маршрутизации должна фиксировать попадания в кэш как свидетельство экономии, а не как разрешение игнорировать лимиты токенов.
Резервируйте место для вывода, рассуждений и инструментов
Маршрутизация по контекстному окну часто дает сбой, потому что команды считают только входные токены. Модели все еще нужно место для ответа.
Для каждого маршрута определите:
- Максимальное количество входных токенов: самый большой запрос, который может принять маршрут.
- Зарезервированные выходные токены: место для видимого ответа, JSON, цитат или аргументов инструментов.
- Зарезервированные токены для рассуждений: дополнительное место для моделей, выполняющих рассуждения, или для сложных задач.
- Накладные расходы на инструменты: определения инструментов, вызовы инструментов и результаты инструментов.
- Запас прочности: буфер для вариативности токенизатора и роста промпта.
Используйте защитный механизм маршрута, подобный этому:
route: contract_review_long_context
max_context_window_tokens: provider_model_limit
max_input_tokens: 180000
reserved_output_tokens: 12000
reserved_reasoning_tokens: 25000
tool_overhead_tokens: 5000
safety_margin_tokens: 8000
on_over_budget:
first: summarize_or_retrieve
second: ask_for_scope_reduction
blocked: send_anywayПриведенные выше числа являются примерами, а не универсальными лимитами. Важна сама структура защитного механизма: маршрут имеет потолок для ввода, резерв для ответа, резерв для рассуждений и явное поведение при превышении бюджета.
Контроль затрат при маршрутизации по контекстному окну
Не измеряйте стоимость только за токен. Измеряйте стоимость за принятый результат.
| Метрика затрат | Почему это важно |
|---|---|
| Стоимость за запрос | Позволяет отловить слишком большие единичные вызовы |
| Стоимость за принятый ответ | Учитывает повторные попытки, неудачное извлечение и неудачные вызовы с длинным контекстом |
| Стоимость за рабочий процесс | Показывает истинную стоимость тикета, обзора, извлечения или отчета |
| Стоимость на владельца | Связывает использование с приложением, командой, клиентом или средой |
| Стоимость ввода с поправкой на кэш | Отделяет повторяющиеся стабильные префиксы от динамического контекста |
| Стоимость резервного варианта | Показывает, спасает ли резервный вариант надежность или скрывает плохой основной маршрут |
Публичный интерфейс продукта Flatkey важен, поскольку он позиционирует платформу вокруг унифицированного доступа к моделям, маршрутизации, биллинга, аналитики использования и операционного контроля. Проверка цен через API в реальном времени для этой статьи 2 июля 2026 года вернула success: true и показала семейства конечных точек, включая openai, anthropic, gemini, image-generation, openai-video и video. Рассматривайте это как устаревшие данные для планирования маршрутов, а не как обещание, что каждая модель, цена или конечная точка останутся неизменными.
Шаблон политики маршрутизации по контекстному окну
Представьте правила в формате, который смогут проверить инженерный, финансовый и закупочный отделы.
policy_name: context_window_routing_v1
owner:
team: ai_platform
approvers:
- engineering
- finance
workflow_classes:
short_task:
max_input_tokens: 8000
route: efficient_text_route
fallback: retry_same_route_once
normal_chat:
max_input_tokens: 32000
route: balanced_tool_route
fallback: reviewed_balanced_backup
long_document_review:
max_input_tokens: 180000
route: long_context_route
fallback: summarize_then_retry
huge_corpus_question:
route: retrieval_first_route
fallback: scoped_long_context_route
budget_rules:
reserve_output_tokens: required_by_workflow
reserve_reasoning_tokens: required_by_model_class
block_when_over_budget: true
require_cache_metrics_when_prompt_repeats: true
evidence:
required_fields:
- workflow_class
- requested_model
- served_model
- endpoint_family
- input_tokens
- cached_tokens
- output_tokens
- reasoning_tokens
- route_decision
- fallback_reason
- owner_key
- cost_or_balance_impact
acceptance_tests:
max_incomplete_rate: agreed_threshold
max_over_budget_rate: zero_for_production
min_answer_acceptance_rate: workflow_eval_threshold
finance_reconciliation_sample: requiredЭтот шаблон делает маршрутизацию по контекстному окну тестируемой. Если маршрут меняется, владелец может увидеть причину. Если промпт растет, защитный механизм может его заблокировать. Если запрос повторяется, метрики кэша становятся частью проверки.
Приемочные тесты перед запуском в продакшен
Выполните эти тесты, прежде чем позволить маршрутизации по контекстному окну обрабатывать продакшен-трафик:
- Отправьте короткий промпт и убедитесь, что он не использует маршрут для длинного контекста.
- Отправьте обычный чат-промпт с инструментами и убедитесь, что определения инструментов и результаты учитываются.
- Отправьте промпт с длинным документом и проверьте, что зарезервированное место для вывода остается доступным.
- Отправьте промпт, превышающий бюджет, и убедитесь, что маршрут выполняет суммаризацию, извлечение данных или запрашивает сужение области поиска вместо слепой отправки.
- Запустите задачу, требующую интенсивных рассуждений, и проверьте обработку неполных ответов.
- Повторите стабильный длинный промпт и убедитесь, что метрики кэшированных токенов записываются, когда провайдер их предоставляет.
- Сравните ответы, полученные сперва через извлечение данных и с полным контекстом, на одном и том же наборе для оценки.
- Проверьте в логах запрошенную модель, обслужившую модель, семейство конечных точек, единицы использования, причину отката и влияние на стоимость или баланс.
Для более широкой архитектуры сочетайте эти проверки с руководствами Flatkey по шлюзам AI API, архитектуре шлюзов LLM API, балансировке нагрузки и отказоустойчивости AI API и проектированию политики маршрутизации моделей.
Какое место занимает Flatkey
Flatkey не должен быть единственным местом, где существует политика. Он должен быть местом, где команды могут упростить выполнение и проверку политики.
Используйте Flatkey для централизации доступа к моделям, проверки маршрутов, текущих цен, видимости использования, квот, логов запросов и проверки биллинга. Затем храните политику маршрутизации по контекстному окну в коде или конфигурации, чтобы решения о маршрутизации были воспроизводимы. Шлюз предоставляет финансовому и операционному отделам более понятное место для проверки использования; политика сообщает инженерному отделу, какой маршрут разрешен.
Практический тестовый запуск Flatkey выглядит так:
- Выберите один рабочий процесс с известными диапазонами размеров промптов.
- Проверьте текущие модели и опции конечных точек на странице цен Flatkey.
- Запустите короткие, обычные, длинные, превышающие бюджет и повторяющиеся кэшируемые промпты.
- Проверьте логи запросов на предмет решения о маршруте, обслужившей модели, использования, полей кэша (где доступно), причины отката и ключа владельца.
- Подтвердите поведение квот и проверки затрат с владельцем рабочего процесса.
- Переносите в продакшен только протестированные маршруты, затем расширяйте маршрутизацию по контекстному окну поэтапно.
Когда тест будет пройден, получите ключ и сделайте первый запуск ограниченным. Смысл маршрутизации по контекстному окну не в том, чтобы добавить сложности, а в том, чтобы остановить незаметный рост промптов, который превращается в неконтролируемые затраты, неполные ответы и не поддающийся проверке выбор моделей.
Часто задаваемые вопросы
Что такое маршрутизация по контекстному окну?
Маршрутизация по контекстному окну — это политика, которая выбирает маршрут модели, путь извлечения, путь сжатия или поведение отклонения на основе размера промпта, резерва для вывода, резерва для рассуждений, накладных расходов на инструменты, контроля затрат и требуемых доказательств.
Чем маршрутизация по контекстному окну отличается от маршрутизации моделей?
Маршрутизация моделей может выбирать по качеству, цене, задержке, модальности, региону или провайдеру. Маршрутизация по контекстному окну фокусируется на том, соответствует ли запрос доступному бюджету контекста и является ли выбор маршрута с меньшим контекстом, с предварительным извлечением, кэшированного или с длинным контекстом правильным решением для контроля затрат.
Когда команде следует использовать извлечение данных вместо модели с длинным контекстом?
Используйте извлечение, когда ответ зависит от небольшой части большого корпуса, когда важны разрешения или когда повторный ввод полного контекста будет дорогостоящим. Используйте длинный контекст, когда задача требует широкого сравнения многих удаленных частей источника.
Зачем резервировать токены для вывода и рассуждений?
Промпт может поместиться во входную часть контекстного окна, но все равно завершиться неудачей, потому что не останется достаточно места для рассуждений или видимого ответа. Резервирование токенов для вывода и рассуждений сокращает количество неполных ответов и бесполезных трат.
Устраняет ли кэширование промптов необходимость в маршрутизации по контекстному окну?
Нет. Кэширование промптов может снизить задержку или стоимость ввода для повторяющихся префиксов, но кэшированные токены все равно необходимо учитывать в контекстном окне. Маршрутизация по контекстному окну должна регистрировать метрики кэшированных токенов, при этом соблюдая бюджетные ограничения.
Как Flatkey помогает с маршрутизацией по контекстному окну?
Flatkey предоставляет командам единый шлюз для доступа к моделям, проверки маршрутов, цен, аналитики использования, журналов запросов, квот и проверки счетов. Это упрощает проверку того, контролирует ли маршрутизация по контекстному окну размер промпта и затраты в соответствии с планом.