Los prompts largos no son automáticamente un problema de contexto largo. Algunos prompts deben recortarse, otros deben usar recuperación, otros deben reservar más espacio de salida y algunos realmente necesitan una ventana de contexto más grande. El enrutamiento por ventana de contexto es la política que decide qué ruta debe tomar una solicitud antes de que gaste presupuesto en el modelo equivocado.
El objetivo es simple: enrutar por el tamaño real del prompt, la forma de la respuesta requerida y la evidencia que necesitas para el control de costes. Una conversación de soporte de 6000 tokens, una revisión de contrato de 70 000 tokens y un escaneo de base de código de 900 000 tokens no deberían compartir una única ruta predeterminada solo porque todos caben detrás de la misma clave de API.
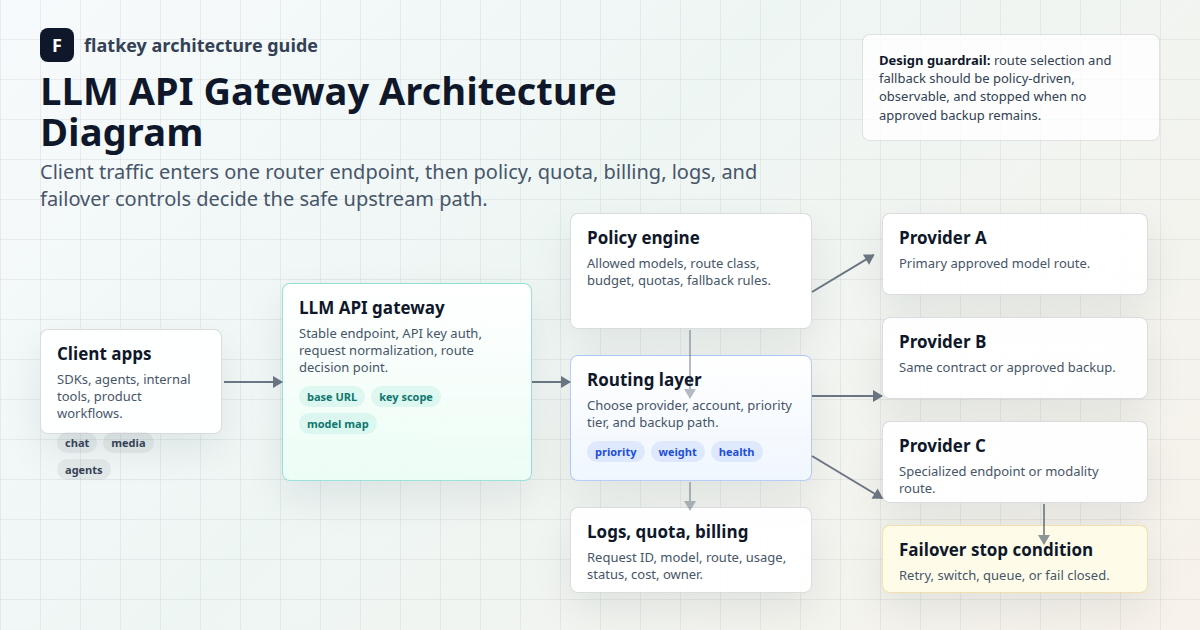
Flatkey es útil en este diseño porque el acceso a los modelos, el enrutamiento, la revisión del uso, la facturación y los controles operativos son más fáciles de gestionar desde una única superficie de puerta de enlace que desde cuentas de proveedores dispersas. Usa el marco a continuación para diseñar reglas de enrutamiento por ventana de contexto, luego valida la fila del modelo actual, la familia de endpoints y la unidad de uso en los precios de Flatkey antes del despliegue en producción.
El enrutamiento por ventana de contexto comienza con un presupuesto de tokens
Comienza cada decisión de ruta con un presupuesto, no con el nombre de un modelo.
required_context =
system_and_policy_tokens
+ user_input_tokens
+ retrieved_or_attached_context_tokens
+ tool_schema_and_tool_result_tokens
+ conversation_history_tokens
+ reserved_output_tokens
+ reserved_reasoning_tokens
+ safety_margin_tokensLa ruta es elegible solo si el contexto requerido se ajusta a la ventana de contexto utilizable del modelo después de que reserves espacio para la salida y el razonamiento. La guía de modelos de razonamiento de OpenAI es un buen recordatorio aquí: cuando los tokens generados alcanzan la ventana de contexto o max_output_tokens, la respuesta puede volverse incompleta, y los equipos deben dejar espacio para el razonamiento y la salida mientras calibran la carga de trabajo.
Esa reserva es importante para el control de costes. Si una solicitud apenas cabe en la ventana de contexto, el modelo aún puede fallar, truncar o gastar mucho en tokens de entrada antes de devolver una respuesta inutilizable. Un buen enrutamiento por ventana de contexto protege contra eso al dirigir las solicitudes de gran tamaño a la ruta correcta antes de que se realice la llamada.
Una matriz de enrutamiento práctica
Usa esta matriz como una primera aproximación para el enrutamiento por ventana de contexto. Ajusta los umbrales en función de tus recuentos de tokens reales, catálogo de modelos, SLO de latencia y evaluaciones de calidad.
| Clase de prompt | Señal típica | Ruta recomendada | Regla de control de costes | Evidencia requerida |
|---|---|---|---|---|
| Tarea corta | Prompt pequeño, respuesta pequeña, sin historial largo | Ruta rápida de bajo coste | Evitar modelos de contexto largo a menos que las evaluaciones lo requieran | Tokens de prompt, tokens de salida, tasa de éxito |
| Chat normal | Historial moderado, herramientas o respuesta estructurada | Ruta equilibrada con soporte para herramientas y esquemas | Limitar por conversación o propietario | Modelo servido, tamaño del resultado de la herramienta, tasa de esquemas válidos |
| Documento largo | Archivo grande, transcripción, política o contrato | Ruta de contexto largo o ruta de recuperación | Comparar el coste del contexto completo con el coste de la recuperación | Tokens de entrada, fragmentos citados, calidad de la respuesta |
| Corpus enorme | Muchos archivos, base de código, registros o archivo | Recuperación, fragmentación, compactación y luego ruta selectiva de contexto largo | No rellenar el corpus por defecto | Fragmentos recuperados, contexto descartado, tasa de aciertos de caché |
| Prompt con mucho razonamiento | Tarea larga más planificación, herramientas o razonamiento de código | Ruta con reserva explícita de salida y razonamiento | Reservar espacio de salida antes de enviar el prompt | Tasa de incompletitud, tokens de razonamiento/salida, latencia p95 |
| Revisión de cumplimiento o finanzas | Contenido sensible y requisitos de auditoría | Ruta revisada y fijada | Bloquear el fallback automático a menos que se apruebe | Modelo solicitado, modelo servido, propietario, traza de coste |
Esto es el enrutamiento por ventana de contexto en forma operativa: cada clase tiene una ruta, una regla de coste y una prueba de que la ruta funcionó.
No uses la ventana de contexto más grande por defecto
Las ventanas de contexto grandes son útiles. No son un reemplazo gratuito para el enrutamiento.
La documentación de contexto largo de Gemini de Google describe ventanas de contexto de 1 millón de tokens y explica cómo el contexto largo puede desbloquear flujos de trabajo que antes necesitaban resumen, recuperación o filtrado. La documentación sobre la ventana de contexto de Anthropic describe el contexto como la memoria de trabajo que incluye el contenido de la solicitud, los resultados de las herramientas, los documentos, las definiciones de las herramientas y la salida. Ambos puntos son importantes: las ventanas más grandes amplían lo que es posible, pero todo lo que colocas en la ventana aún debe pagarse, validarse y registrarse.
La opción predeterminada más segura no es "enviarlo todo". La opción predeterminada más segura es:
- Mantener los prompts cortos en rutas eficientes.
- Usar la recuperación cuando la respuesta depende de una pequeña porción de un corpus grande.
- Usar el contexto largo cuando el modelo debe comparar muchas partes de la fuente a la vez.
- Reservar presupuesto para la salida y el razonamiento antes de llamar a un modelo de razonamiento.
- Registrar suficientes detalles de uso para comparar el coste por resultado aceptado.
Ese es el núcleo del control de costes del enrutamiento por ventana de contexto.
Cuándo la recuperación supera al contexto largo
La recuperación suele ser mejor cuando la tarea tiene una necesidad de evidencia limitada. Algunos ejemplos son "encontrar la cláusula de renovación", "resumir este incidente a partir de las tres líneas de registro pertinentes" o "responder a partir de la documentación actual de la API". En esos casos, enviar todo el contrato, el archivo de registros o el sitio de documentación puede aumentar el coste sin mejorar la precisión.
Usa la recuperación cuando:
- La respuesta debe citar un número reducido de pasajes.
- La mayor parte del corpus es irrelevante para la pregunta del usuario.
- Muchos usuarios consultan repetidamente el mismo corpus.
- Necesitas restringir la exposición de datos por inquilino, proyecto, equipo o permiso.
- El coste de la entrada de contexto completo superaría el valor de la respuesta.
El enrutamiento de la ventana de contexto debe enviar primero la solicitud a través de la recuperación y, a continuación, pasar solo los fragmentos, metadatos e instrucciones seleccionados al modelo. Registra los ID de origen recuperados, el recuento de tokens y el resultado de aceptación de la respuesta. Si la respuesta falla porque faltaba demasiado contexto, promueve ese flujo de trabajo a una ruta de contexto más grande y registra el motivo.
Cuando el contexto largo supera a la recuperación
El contexto largo es más potente cuando la tarea necesita una comparación amplia. Algunos ejemplos son la revisión de un conjunto completo de políticas en busca de contradicciones, el análisis de una transcripción completa, la comparación de secciones en un contrato extenso o el uso de un repositorio completo como conjunto de referencia para una tarea de planificación.
Usa una ruta de contexto largo cuando:
- La tarea depende de las relaciones entre muchas secciones distantes.
- El modelo necesita toda la estructura del documento, no solo pasajes aislados.
- La calidad de la recuperación es difícil de verificar antes de la generación.
- La fuente es un único artefacto delimitado, como un PDF, una transcripción o un paquete de código.
- El valor esperado de la respuesta justifica el mayor coste de entrada.
Incluso en ese caso, el enrutamiento de la ventana de contexto no debe omitir las comprobaciones de costes. Mide los tokens de entrada completos, los tokens en caché si están disponibles, los tokens de salida, la latencia, la tasa de reintentos y la tasa de respuestas aceptadas. La política de enrutamiento debe demostrar que la ruta de contexto largo fue mejor que la de recuperación, no solo más fácil de implementar.
El almacenamiento en caché de prompts forma parte de la decisión de enrutamiento
El almacenamiento en caché de prompts puede cambiar la economía de los prompts largos repetidos. La documentación sobre el almacenamiento en caché de prompts de OpenAI explica que los prompts largos que cumplen los requisitos pueden beneficiarse cuando el contenido estático aparece primero y el contenido variable después; también exponen cached_tokens en los detalles de uso para que los equipos puedan supervisar el comportamiento de la caché.
El enrutamiento de la ventana de contexto debe tratar la capacidad de almacenamiento en caché como una señal de primera clase:
| Patrón de prompt | Implicación para el enrutamiento |
|---|---|
| Política de sistema estable más muchas preguntas de usuario | Poner primero el contenido estable y medir la proporción de tokens en caché |
| Paquete de documentación grande y repetido | Considerar una ruta de contexto largo que tenga en cuenta la caché |
| Datos muy dinámicos y específicos del usuario | No asumir ahorros por la caché |
| Definiciones de herramientas compartidas en muchas llamadas | Mantener los esquemas de las herramientas estables siempre que sea posible |
| Prompt corto por debajo del umbral de la caché | Optimizar primero la ruta/modelo; el almacenamiento en caché puede no ayudar |
Los tokens en caché pueden reducir el coste o la latencia en función del comportamiento del proveedor, pero no hacen que la ventana de contexto sea infinita. La documentación de Anthropic hace la importante distinción directamente: los prefijos de prompt en caché pueden seguir ocupando la ventana de contexto. La política de enrutamiento debe registrar los aciertos de caché como prueba de coste, no como permiso para ignorar los límites de tokens.
Reservar espacio para la salida, el razonamiento y las herramientas
El enrutamiento de la ventana de contexto suele fallar porque los equipos solo cuentan los tokens de entrada. El modelo todavía necesita espacio para responder.
Para cada ruta, define:
- Tokens de entrada máximos: la solicitud más grande que la ruta puede aceptar.
- Tokens de salida reservados: espacio para la respuesta visible, JSON, citas o argumentos de herramientas.
- Tokens de razonamiento reservados: espacio extra para modelos de razonamiento o tareas difíciles.
- Sobrecarga de herramientas: definiciones de herramientas, llamadas a herramientas y resultados de herramientas.
- Margen de seguridad: un búfer para la varianza del tokenizador y el crecimiento del prompt.
Utiliza un guardián de ruta como este:
route: contract_review_long_context
max_context_window_tokens: provider_model_limit
max_input_tokens: 180000
reserved_output_tokens: 12000
reserved_reasoning_tokens: 25000
tool_overhead_tokens: 5000
safety_margin_tokens: 8000
on_over_budget:
first: summarize_or_retrieve
second: ask_for_scope_reduction
blocked: send_anywayLos números anteriores son marcadores de posición, no límites universales. Lo importante es la forma de la barrera de protección: la ruta tiene un límite de entrada, una reserva de respuesta, una reserva de razonamiento y un comportamiento explícito para cuando se excede el presupuesto.
Controles de costes para el enrutamiento de la ventana de contexto
No midas el coste solo por token. Mide el coste por resultado aceptado.
| Métrica de coste | Por qué es importante |
|---|---|
| Coste por solicitud | Detecta llamadas individuales sobredimensionadas |
| Coste por respuesta aceptada | Tiene en cuenta los reintentos, la mala recuperación y las llamadas de contexto largo fallidas |
| Coste por flujo de trabajo | Muestra el coste real de un ticket, una revisión, una extracción o un informe |
| Coste por propietario | Conecta el uso con la aplicación, el equipo, el cliente o el entorno |
| Coste de entrada ajustado por caché | Separa los prefijos estables repetidos del contexto dinámico |
| Coste de respaldo | Muestra si el respaldo está rescatando la fiabilidad o ocultando una ruta principal defectuosa |
La superficie de producto pública de Flatkey es relevante porque posiciona la plataforma en torno al acceso unificado a modelos, enrutamiento, facturación, análisis de uso y controles operativos. La comprobación de la API de precios en tiempo real para este artículo el 2 de julio de 2026 devolvió success: true y expuso familias de endpoints que incluyen openai, anthropic, gemini, image-generation, openai-video y video. Considere esto como una evidencia fechada para la planificación de rutas, no como una promesa de que todos los modelos, precios o endpoints permanecerán sin cambios.
Una plantilla de política de enrutamiento por ventana de contexto
Ponga las reglas en un formato que los equipos de ingeniería, finanzas y adquisiciones puedan revisar.
policy_name: context_window_routing_v1
owner:
team: ai_platform
approvers:
- engineering
- finance
workflow_classes:
short_task:
max_input_tokens: 8000
route: efficient_text_route
fallback: retry_same_route_once
normal_chat:
max_input_tokens: 32000
route: balanced_tool_route
fallback: reviewed_balanced_backup
long_document_review:
max_input_tokens: 180000
route: long_context_route
fallback: summarize_then_retry
huge_corpus_question:
route: retrieval_first_route
fallback: scoped_long_context_route
budget_rules:
reserve_output_tokens: required_by_workflow
reserve_reasoning_tokens: required_by_model_class
block_when_over_budget: true
require_cache_metrics_when_prompt_repeats: true
evidence:
required_fields:
- workflow_class
- requested_model
- served_model
- endpoint_family
- input_tokens
- cached_tokens
- output_tokens
- reasoning_tokens
- route_decision
- fallback_reason
- owner_key
- cost_or_balance_impact
acceptance_tests:
max_incomplete_rate: agreed_threshold
max_over_budget_rate: zero_for_production
min_answer_acceptance_rate: workflow_eval_threshold
finance_reconciliation_sample: requiredEsta plantilla hace que el enrutamiento por ventana de contexto sea comprobable. Si la ruta cambia, el propietario puede ver por qué. Si el prompt crece, la barrera de protección puede bloquearlo. Si la solicitud se repite, las métricas de caché pasan a formar parte de la revisión.
Pruebas de aceptación antes de la producción
Ejecute estas pruebas antes de permitir que el enrutamiento por ventana de contexto gestione el tráfico de producción:
- Envíe un prompt corto y confirme que se mantiene fuera de la ruta de contexto largo.
- Envíe un prompt de chat normal con herramientas y confirme que las definiciones de las herramientas y los resultados se cuentan.
- Envíe un prompt de documento largo y verifique que el espacio de salida reservado permanezca disponible.
- Envíe un prompt que exceda el presupuesto y confirme que la ruta resume, recupera o solicita una reducción del alcance en lugar de enviarlo a ciegas.
- Desencadene una tarea que requiera mucho razonamiento y compruebe el manejo de respuestas incompletas.
- Repita un prompt largo y estable y confirme que las métricas de tokens en caché se registran cuando el proveedor las expone.
- Compare las respuestas de recuperación primero y de contexto completo en el mismo conjunto de evaluación.
- Revise el modelo solicitado, el modelo servido, la familia de endpoints, las unidades de uso, el motivo del fallback y el impacto en el costo o el saldo en los registros.
Para una arquitectura más amplia, combine estas comprobaciones con las guías de Flatkey sobre gateways de API de IA, arquitectura de gateway de API de LLM, balanceo de carga y conmutación por error de API de IA y diseño de políticas de enrutamiento de modelos.
Dónde encaja Flatkey
Flatkey no debería ser el único lugar donde exista la política. Debería ser el lugar donde los equipos puedan hacer que la política sea más fácil de ejecutar y revisar.
Use Flatkey para centralizar el acceso a los modelos, la revisión de rutas, las comprobaciones de precios actuales, la visibilidad del uso, las cuotas, los registros de solicitudes y la revisión de la facturación. Luego, mantenga la política de enrutamiento por ventana de contexto en el código o la configuración para que las decisiones de enrutamiento sean repetibles. El gateway ofrece a los equipos de finanzas y operaciones un lugar más claro para inspeccionar el uso; la política le dice a ingeniería qué ruta está permitida.
Una prueba de concepto práctica de Flatkey se ve así:
- Elija un flujo de trabajo con rangos de tamaño de prompt conocidos.
- Compruebe las opciones actuales de modelos y endpoints en los precios de Flatkey.
- Ejecute prompts cortos, normales, largos, que excedan el presupuesto y repetidos que se puedan almacenar en caché.
- Revise los registros de solicitudes para ver la decisión de la ruta, el modelo servido, el uso, los campos de caché donde estén disponibles, el motivo del fallback y la clave del propietario.
- Confirme el comportamiento de la cuota y la revisión de costos con el propietario del flujo de trabajo.
- Mueva solo las rutas probadas a producción, y luego expanda el enrutamiento por ventana de contexto fila por fila.
Cuando la prueba pase, obtenga una clave y mantenga el primer despliegue limitado. El objetivo del enrutamiento por ventana de contexto no es añadir complejidad; es evitar que el crecimiento de los prompts se convierta silenciosamente en un costo descontrolado, respuestas incompletas y elecciones de modelos no revisables.
Preguntas frecuentes
¿Qué es el enrutamiento por ventana de contexto?
El enrutamiento por ventana de contexto es una política que elige la ruta del modelo, la ruta de recuperación, la ruta de compactación o el comportamiento de rechazo en función del tamaño del prompt, la reserva de salida, la reserva de razonamiento, la sobrecarga de herramientas, los controles de costos y la evidencia requerida.
¿En qué se diferencia el enrutamiento por ventana de contexto del enrutamiento de modelos?
El enrutamiento de modelos puede elegir por calidad, precio, latencia, modalidad, región o proveedor. El enrutamiento por ventana de contexto se centra en si la solicitud se ajusta al presupuesto de contexto utilizable y si una ruta más pequeña, de recuperación primero, en caché o de contexto largo es la opción correcta para el control de costos.
¿Cuándo debería un equipo usar la recuperación en lugar de un modelo de contexto largo?
Use la recuperación cuando la respuesta dependa de una pequeña parte de un gran corpus, cuando los permisos importen o cuando la entrada repetida de contexto completo sea costosa. Use el contexto largo cuando la tarea necesite una comparación amplia entre muchas partes distantes de la fuente.
¿Por qué reservar tokens de salida y de razonamiento?
Un prompt puede caber en el lado de entrada de la ventana de contexto y aun así fallar porque no queda suficiente espacio para el razonamiento o la respuesta visible. Reservar tokens de salida y de razonamiento reduce las respuestas incompletas y el gasto desperdiciado.
¿El almacenamiento en caché de prompts elimina la necesidad de enrutamiento de la ventana de contexto?
No. El almacenamiento en caché de prompts puede reducir la latencia o el coste de entrada para prefijos repetidos, pero los tokens almacenados en caché aún deben tenerse en cuenta en la ventana de contexto. El enrutamiento de la ventana de contexto debe registrar las métricas de los tokens almacenados en caché sin dejar de aplicar los límites presupuestarios.
¿Cómo ayuda Flatkey con el enrutamiento de la ventana de contexto?
Flatkey ofrece a los equipos una única superficie de puerta de enlace para el acceso a modelos, la revisión de rutas, las comprobaciones de precios, los análisis de uso, los registros de solicitudes, las cuotas y la revisión de la facturación. Eso facilita la validación de si el enrutamiento de la ventana de contexto está controlando el tamaño del prompt y el coste según lo diseñado.