长提示词并不自动等同于长上下文问题。有些提示词应该被修剪,有些应该使用检索,有些应该保留更多的输出空间,而有些确实需要更大的上下文窗口。上下文窗口路由是一种策略,它决定了在请求因选择了错误的模型而耗尽预算之前,应该采取哪条路径。
目标很简单:根据实际的提示词大小、所需的答案形态以及成本控制所需的证据进行路由。一个 6,000 token 的支持对话、一个 70,000 token 的合同审查和一个 900,000 token 的代码库扫描,不应该仅仅因为它们都使用同一个 API 密钥就共享同一条默认路由。
Flatkey 在此设计中非常有用,因为模型访问、路由、用量审查、计费和操作控制通过一个网关界面进行管理,比通过分散的提供商账户更容易。使用下面的框架来设计上下文窗口路由规则,然后在生产部署前在 Flatkey 定价页面上验证当前的模型行、端点系列和使用单位。
上下文窗口路由始于 token 预算
每个路由决策都应从预算开始,而不是模型名称。
required_context =
system_and_policy_tokens
+ user_input_tokens
+ retrieved_or_attached_context_tokens
+ tool_schema_and_tool_result_tokens
+ conversation_history_tokens
+ reserved_output_tokens
+ reserved_reasoning_tokens
+ safety_margin_tokens只有在为输出和推理保留空间后,所需的上下文大小符合模型的可用上下文窗口时,该路由才符合条件。OpenAI 的推理模型指南在这里是一个很好的提醒:当生成的 token 达到上下文窗口或 max_output_tokens 时,响应可能会不完整,团队在校准工作负载时应为推理和输出留出空间。
这种保留对于成本控制至关重要。如果一个请求勉强符合上下文窗口的大小,模型仍可能失败、截断或在返回一个无法使用的答案之前在输入 token 上花费大量资金。良好的上下文窗口路由通过在调用前将超大请求路由到正确的路径来防止这种情况发生。
一个实用的路由矩阵
使用此矩阵作为上下文窗口路由的初稿。根据您的实际 token 数量、模型目录、延迟 SLO 和质量评估来调整阈值。
| 提示词类别 | 典型信号 | 推荐路由 | 成本控制规则 | 所需证据 |
|---|---|---|---|---|
| 短任务 | 小提示词、小答案、无长历史记录 | 快速低成本路由 | 除非评估需要,否则避免使用长上下文模型 | 提示词 token、输出 token、成功率 |
| 普通聊天 | 中等长度历史记录、工具或结构化答案 | 支持工具和模式的均衡路由 | 按对话或所有者设置上限 | 服务的模型、工具结果大小、模式有效率 |
| 长文档 | 大文件、转录稿、政策或合同 | 长上下文路由或检索路由 | 比较完整上下文成本与检索成本 | 输入 token、引用的片段、答案质量 |
| 巨大语料库 | 许多文件、代码库、日志或存档 | 检索、分块、压缩,然后选择性长上下文路由 | 默认情况下不要填充整个语料库 | 检索到的块、丢弃的上下文、缓存命中率 |
| 重推理提示词 | 长任务加上规划、工具或代码推理 | 具有明确输出和推理保留的路由 | 发送提示词前保留输出空间 | 不完整率、推理/输出 token、p95 延迟 |
| 合规或财务审查 | 敏感内容和审计要求 | 固定的已审查路由 | 除非获得批准,否则阻止自动回退 | 请求的模型、服务的模型、所有者、成本追溯 |
这就是操作形式的上下文窗口路由:每个类别都有一个路由、一个成本规则以及证明该路由有效的证据。
不要将最大的上下文窗口用作默认设置
大上下文窗口很有用。但它们不能免费替代路由。
Google 的 Gemini 长上下文文档描述了 100 万 token 的上下文窗口,并解释了长上下文如何解锁以前需要摘要、检索或过滤的工作流。Anthropic 的上下文窗口文档将上下文描述为工作内存,包括请求内容、工具结果、文档、工具定义和输出。这两点都很重要:更大的窗口扩展了可能性,但放入窗口的所有内容仍然需要付费、验证和记录。
最安全的默认设置不是“发送所有内容”。更安全的默认设置是:
- 将短提示词保留在高效路由上。
- 当答案依赖于大型语料库的一小部分时,使用检索。
- 当模型必须同时比较源的多个部分时,使用长上下文。
- 在调用推理模型之前,保留输出和推理预算。
- 记录足够的用量细节,以比较每个可接受结果的成本。
这就是上下文窗口路由的成本控制核心。
何时检索优于长上下文
当任务需要狭窄的证据时,检索通常效果更好。例如,“查找续订条款”、“根据三条相关的日志行总结此事件”或“根据当前的 API 文档回答”。在这些情况下,发送整个合同、日志存档或文档站点可能会增加成本,而不会提高准确性。
在以下情况下使用检索:
- 答案应引用少量段落。
- 语料库的大部分内容与用户问题无关。
- 许多用户重复查询同一个语料库。
- 您需要按租户、项目、团队或权限限制数据暴露。
- 完整上下文输入的成本将超过答案的价值。
上下文窗口路由应首先通过检索发送请求,然后仅将选定的块、元数据和指令传递给模型。记录检索到的源 ID、令牌计数和答案接受结果。如果由于缺少太多上下文而导致答案失败,请将该工作流提升到更大的上下文路由并记录原因。
长上下文何时优于检索
当任务需要广泛比较时,长上下文更具优势。例如,审查整套政策是否存在矛盾、分析完整的文字记录、比较大型合同中的不同部分,或将整个存储库用作规划任务的参考集。
在以下情况下使用长上下文路由:
- 任务依赖于许多远距离部分之间的关系。
- 模型需要整个文档结构,而不仅仅是孤立的段落。
- 在生成之前很难验证检索质量。
- 来源是单个有界的人工制品,例如一个 PDF、一份文字记录或一个代码包。
- 答案的预期价值证明了更大的输入成本是合理的。
即便如此,上下文窗口路由也不应跳过成本检查。测量完整的输入令牌、可用的缓存令牌、输出令牌、延迟、重试率和接受答案率。路由策略应证明长上下文路由优于检索,而不仅仅是更容易实现。
提示词缓存属于路由决策的一部分
提示词缓存可以改变重复长提示词的经济性。OpenAI 的提示词缓存文档解释说,当静态内容先出现而可变内容后出现时,符合条件的长提示词可以受益;他们还在使用详情中公开了 cached_tokens,以便团队可以监控缓存行为。
上下文窗口路由应将可缓存性视为一等信号:
| 提示词模式 | 路由影响 |
|---|---|
| 稳定的系统策略加上许多用户问题 | 将稳定内容放在前面并测量缓存令牌份额 |
| 重复的大型文档包 | 考虑缓存感知的长上下文路由 |
| 高度动态的用户特定数据 | 不要假设有缓存节省 |
| 在多个调用中共享的工具定义 | 尽可能保持工具模式稳定 |
| 低于缓存阈值的短提示词 | 首先优化路由/模型;缓存可能没有帮助 |
根据提供商的行为,缓存的令牌可能会降低成本或延迟,但它们不会使上下文窗口变得无限大。Anthropic 的文档直接做出了重要的区分:缓存的提示词前缀仍然会占用上下文窗口。路由策略应将缓存命中记录为成本证据,而不是忽略令牌限制的许可。
保留输出、推理和工具空间
上下文窗口路由经常失败,因为团队只计算输入令牌。模型仍然需要空间来回答。
为每个路由定义:
- 最大输入令牌数: 路由可能接受的最大请求。
- 保留的输出令牌数: 为可见答案、JSON、引文或工具参数留出的空间。
- 保留的推理令牌数: 为推理模型或困难任务留出的额外空间。
- 工具开销: 工具定义、工具调用和工具结果。
- 安全边际: 为分词器差异和提示词增长提供的缓冲。
使用如下的路由守卫:
route: contract_review_long_context
max_context_window_tokens: provider_model_limit
max_input_tokens: 180000
reserved_output_tokens: 12000
reserved_reasoning_tokens: 25000
tool_overhead_tokens: 5000
safety_margin_tokens: 8000
on_over_budget:
first: summarize_or_retrieve
second: ask_for_scope_reduction
blocked: send_anyway上面的数字是占位符,不是通用限制。重要的是防护栏的形态:路由有输入上限、答案保留、推理保留和明确的超预算行为。
上下文窗口路由的成本控制
不要只按令牌衡量成本。要按每个被接受的结果衡量成本。
| 成本指标 | 重要性 |
|---|---|
| 每次请求的成本 | 捕获超大的单次调用 |
| 每个被接受答案的成本 | 考虑了重试、不良检索和失败的长上下文调用 |
| 每个工作流的成本 | 显示工单、审查、提取或报告的真实成本 |
| 每个所有者的成本 | 将使用情况与应用、团队、客户或环境联系起来 |
| 缓存调整后的输入成本 | 将重复的稳定前缀与动态上下文分开 |
| 回退成本 | 显示回退是在挽救可靠性还是在隐藏一个糟糕的主路由 |
Flatkey 的公共产品界面之所以重要,是因为它将平台定位为围绕统一模型访问、路由、计费、使用分析和运营控制。本文在 2026 年 7 月 2 日进行的实时定价 API 检查返回了 success: true,并公开了包括 openai、anthropic、gemini、image-generation、openai-video 和 video 在内的端点系列。请将此视为路由规划的过时证据,而不是每个模型、价格或端点都将保持不变的承诺。
上下文窗口路由策略模板
将规则以工程、财务和采购部门可以审查的格式呈现。
policy_name: context_window_routing_v1
owner:
team: ai_platform
approvers:
- engineering
- finance
workflow_classes:
short_task:
max_input_tokens: 8000
route: efficient_text_route
fallback: retry_same_route_once
normal_chat:
max_input_tokens: 32000
route: balanced_tool_route
fallback: reviewed_balanced_backup
long_document_review:
max_input_tokens: 180000
route: long_context_route
fallback: summarize_then_retry
huge_corpus_question:
route: retrieval_first_route
fallback: scoped_long_context_route
budget_rules:
reserve_output_tokens: required_by_workflow
reserve_reasoning_tokens: required_by_model_class
block_when_over_budget: true
require_cache_metrics_when_prompt_repeats: true
evidence:
required_fields:
- workflow_class
- requested_model
- served_model
- endpoint_family
- input_tokens
- cached_tokens
- output_tokens
- reasoning_tokens
- route_decision
- fallback_reason
- owner_key
- cost_or_balance_impact
acceptance_tests:
max_incomplete_rate: agreed_threshold
max_over_budget_rate: zero_for_production
min_answer_acceptance_rate: workflow_eval_threshold
finance_reconciliation_sample: required此模板使上下文窗口路由变得可测试。如果路由发生变化,所有者可以知道原因。如果提示词变长,护栏可以阻止它。如果请求重复,缓存指标将成为审查的一部分。
生产前的验收测试
在让上下文窗口路由处理生产流量之前,请运行以下测试:
- 发送一个简短的提示词,并确认它没有走长上下文路由。
- 发送一个带工具的普通聊天提示词,并确认工具定义和结果已被计算在内。
- 发送一个长文档提示词,并验证保留的输出空间仍然可用。
- 发送一个超预算的提示词,并确认路由会进行总结、检索或要求缩小范围,而不是盲目发送。
- 触发一个重推理任务,并检查不完整响应的处理情况。
- 重复一个稳定的长提示词,并确认在提供商公开缓存令牌指标时,这些指标已被记录。
- 在同一评估集上比较检索优先和全上下文的答案。
- 在日志中审查请求的模型、服务的模型、端点系列、使用单位、回退原因以及成本或余额影响。
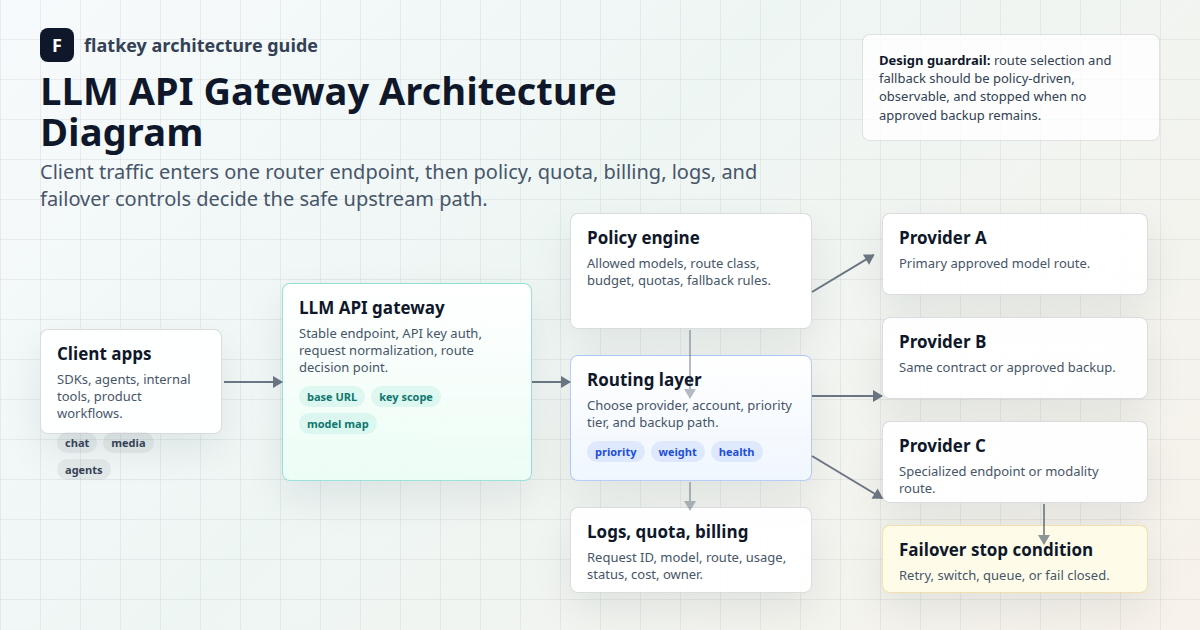
对于更广泛的架构,请将这些检查与 Flatkey 的 AI API 网关、LLM API 网关架构、AI API 负载均衡和故障转移以及模型路由策略设计指南结合使用。
Flatkey 的定位
Flatkey 不应该是策略存在的唯一地方。它应该是团队可以使策略更易于运行和审查的地方。
使用 Flatkey 来集中管理模型访问、路由审查、当前定价检查、使用情况可见性、配额、请求日志和计费审查。然后将上下文窗口路由策略保存在代码或配置中,以便路由决策是可重复的。网关为财务和运营部门提供了一个更清晰的检查使用情况的地方;策略告诉工程部门允许哪条路由。
一个实际的 Flatkey 验证运行如下所示:
- 选择一个具有已知提示词大小范围的工作流。
- 在 Flatkey 定价页面上检查当前的模型和端点选项。
- 运行简短、正常、长、超预算和可重复缓存的提示词。
- 审查请求日志中的路由决策、服务的模型、使用情况、可用的缓存字段、回退原因和所有者密钥。
- 与工作流所有者确认配额和成本审查行为。
- 仅将测试过的路由移至生产环境,然后逐行扩展上下文窗口路由。
当验证通过后,获取一个密钥并保持首次推出的范围较小。上下文窗口路由的重点不是增加复杂性,而是阻止提示词的增长悄然演变成失控的成本、不完整的答案和无法审查的模型选择。
常见问题解答
什么是上下文窗口路由?
上下文窗口路由是一种策略,它根据提示词大小、输出保留、推理保留、工具开销、成本控制和所需证据来选择模型路由、检索路径、压缩路径或拒绝行为。
上下文窗口路由与模型路由有何不同?
模型路由可以根据质量、价格、延迟、模态、地区或提供商进行选择。上下文窗口路由则专注于请求是否符合可用的上下文预算,以及选择更小、检索优先、缓存或长上下文路由是否是正确的成本控制选择。
团队应该在什么时候使用检索而不是长上下文模型?
当答案依赖于大型语料库的一小部分、权限很重要或重复的完整上下文输入成本高昂时,请使用检索。当任务需要在源的许多遥远部分之间进行广泛比较时,请使用长上下文。
为什么要预留输出和推理词元?
一个提示词可能适合上下文窗口的输入端,但仍然会失败,因为没有为推理或可见答案留下足够的空间。预留输出和推理词元可以减少不完整的响应和不必要的开销。
提示词缓存是否消除了对上下文窗口路由的需求?
不会。提示词缓存可以减少重复前缀的延迟或输入成本,但缓存的词元仍需要在上下文窗口中加以考虑。上下文窗口路由应记录缓存词元的指标,同时仍然强制执行预算限制。
Flatkey 如何帮助进行上下文窗口路由?
Flatkey 为团队提供了一个统一的网关界面,用于模型访问、路由审查、定价检查、使用情况分析、请求日志、配额和账单审查。这使得验证上下文窗口路由是否按设计控制提示词大小和成本变得更加容易。